 David Straub
David Straub
Der neue Gramps Web KI-Chat-Assistent – Technische Details
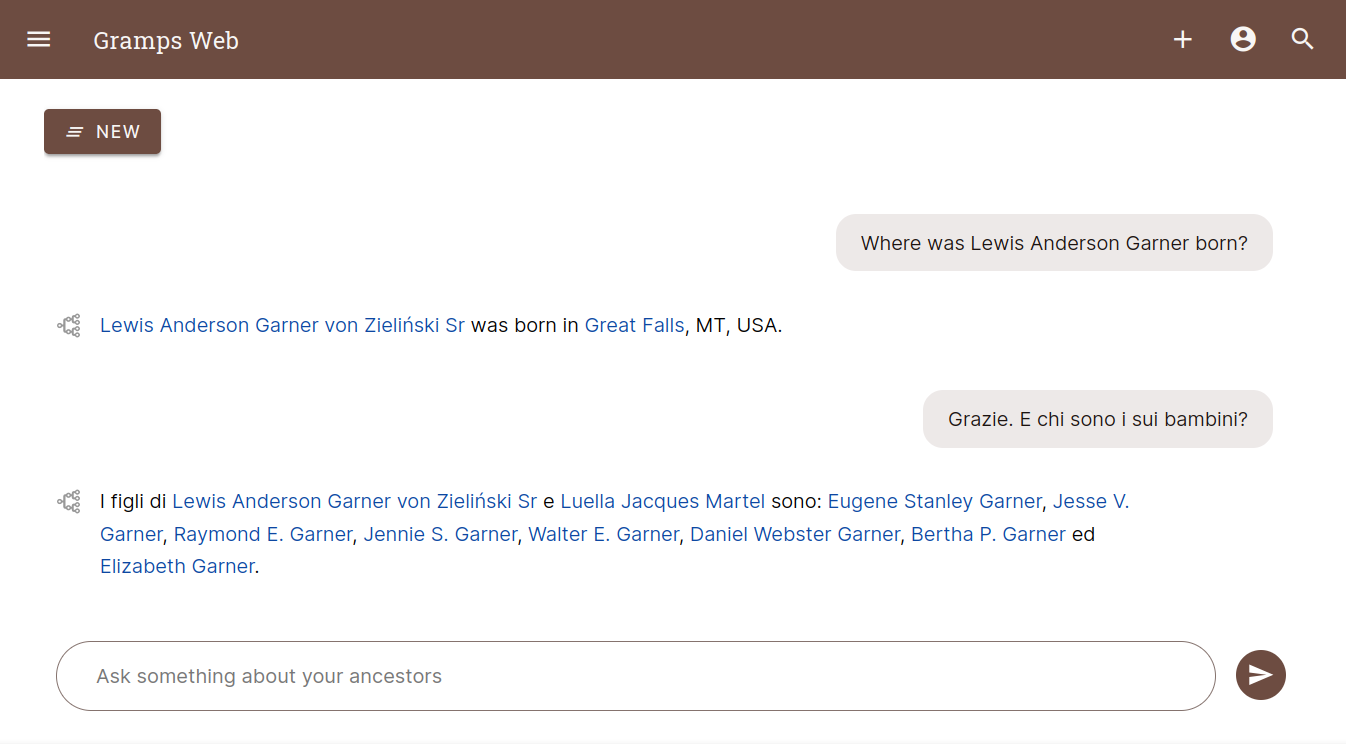
Ab Version 24.10 ist Gramps Web das erste quelloffene Genealogie-System mit einem KI-Chat-Assistenten! In diesem Beitrag geht es um die technische Umsetzung dieses spannenden neuen Features, das es ermöglicht, mit genealogischen Daten per natürlicher Sprache zu interagieren.
Ich erkläre, wie Research Augmented Generation (RAG) den Assistenten antreibt und welche Designentscheidungen getroffen wurden. Im nächsten Beitrag steht die Nutzung aus Anwendersicht im Fokus, mit aktuellen Möglichkeiten und wichtigen Einschränkungen. Der letzte Beitrag richtet sich speziell an Grampshub-Nutzer. Die neue Version wird voraussichtlich im nächsten Monat auf Grampshub verfügbar sein.
Research Augmented Generation
Im Kern des Gramps Web KI-Chat-Assistenten steht die Technik Research Augmented Generation (RAG), die semantische Suche mit großen Sprachmodellen (LLMs) kombiniert. RAG ermöglicht es dem System, Antworten auf Nutzerfragen auf Basis der eigenen genealogischen Datenbank zu formulieren, ohne auf externes Wissen angewiesen zu sein – und das ohne aufwändiges und teures Modelltraining.
So funktioniert RAG:
Semantisches Indexieren: Zunächst werden Objekte der genealogischen Datenbank in Vektor-Embeddings umgewandelt – numerische Repräsentationen, die ihre Bedeutung kodieren. Dies geschieht mit einem vortrainierten Embedding-Modell aus der Open-Source-Bibliothek Sentence Transformers. Die Vektoren bilden die Grundlage für spätere Suchanfragen und ermöglichen dem System, die Inhalte der Datenbank semantisch zu „verstehen“.
Semantische Suche: Wenn ein Nutzer eine Frage im Chat stellt, wird die Anfrage ebenfalls in ein Vektor-Embedding umgewandelt. Das System vergleicht diesen Anfrage-Vektor mit den vorab berechneten Vektoren der Datenbankobjekte und findet per semantischer Ähnlichkeit die relevantesten Ergebnisse.
Antwortgenerierung: Die gefundenen Objekte und die ursprüngliche Nutzerfrage werden dann an ein LLM übergeben. Das LLM fasst die Informationen zusammen und formuliert eine kohärente Antwort, basierend auf den genealogischen Daten und dem Kontext der Frage.
Diese Kombination aus semantischer Suche und LLMs ermöglicht es dem Assistenten, kontextreiche Antworten zu geben, die auf den eigenen genealogischen Daten basieren.
Vektorsuche für semantisches Verständnis
Ein zentrales Element des KI-Assistenten von Gramps Web ist die Vektorsuche, die ein semantisches Verständnis der genealogischen Daten ermöglicht. Im Gegensatz zur klassischen Volltextsuche, die auf Schlüsselwörtern basiert, kann die Vektorsuche die Bedeutung hinter Nutzeranfragen und genealogischen Einträgen erfassen.
Dadurch kann der Assistent eine Vielzahl von Fragen beantworten, auch wenn diese nicht direkt mit dem Text in der Datenbank übereinstimmen. Beispielsweise kann ein Nutzer nach „Familienmitgliedern, die ausgewandert sind“ fragen, ohne das Wort „Auswanderung“ explizit in den Daten zu verwenden – die Vektor-Embeddings erfassen semantische Ähnlichkeiten zwischen verwandten Begriffen und Konzepten.
Die Erweiterung von Gramps Web um semantische Suche wurde durch die Integration der Sifts-Bibliothek erleichtert, die speziell für die Anforderungen von Volltext- und Vektorsuche erweitert wurde. Sifts bietet eine einheitliche, effiziente Schnittstelle für beide Sucharten. Mit Dual-Datenbank-Unterstützung kann nahtlos zwischen SQLite für einfache Setups und PostgreSQL für robuste Produktionsumgebungen gewechselt werden.
Auswahl des Embedding-Modells und Abwägungen
Ein wichtiger Aspekt ist die Auswahl des Vektor-Embedding-Modells, das auf demselben Server wie Gramps Web läuft. Die Sentence Transformers-Bibliothek bietet verschiedene Modelle, aber die Wahl muss zwischen Genauigkeit, Geschwindigkeit und Mehrsprachigkeit abwägen.
Genauigkeit vs. Performance: Größere Modelle bieten bessere semantische Erkennung, benötigen aber mehr Rechenleistung, besonders auf CPUs ohne GPU-Beschleunigung. Da Gramps Web auf unterschiedlichster Hardware läuft – von Desktop-PCs bis zum Raspberry Pi – wurde ein Mittelweg gewählt, der gute Mehrsprachigkeit und Effizienz bietet und in den Docker-Images vorkonfiguriert ist.
Mehrsprachigkeit: Da viele genealogische Daten mehrsprachig sind, war ein Modell mit starker Mehrsprach-Unterstützung entscheidend. So können Nutzer ihre Daten in verschiedenen Sprachen abfragen und der Assistent liefert trotzdem sinnvolle Antworten.
Auswahl des LLM
Obwohl Grampshub eine gehostete Lösung von Gramps Web bietet, die möglichst einfach nutzbar sein soll, ist es immer möglich, Gramps Web selbst auf einem eigenen Server zu betreiben. Nach dieser Philosophie wurde der KI-Chat-Assistent so umgesetzt, dass man auch ein eigenes Open-Source-LLM lokal hosten kann, ohne Daten in die Cloud zu senden. Möglich wird das durch Ollama.
Das Ausführen eines LLM erfordert jedoch erhebliche Rechenressourcen – noch deutlich mehr als die Embedding-Modelle. Daher ist es auch möglich, einen bestehenden LLM-API-Anbieter zu nutzen, z.B. OpenAI oder andere kompatible Anbieter.
So können Nutzer die Lösung wählen, die am besten zur eigenen Infrastruktur passt – ob einfache Nutzung und Skalierbarkeit eines Cloud-LLM oder die Privatsphäre und Kontrolle eines lokal betriebenen Modells.
Datenschutz
Wie überall in Gramps Web hängt die Sichtbarkeit der Daten von den Berechtigungen ab. Nutzer ohne Rechte für als privat markierte Einträge sehen diese auch im Chat nicht, und das LLM erhält diese Daten ebenfalls nicht.
Bei Nutzung einer API ist es wichtig, einen Anbieter zu wählen, der Nutzeranfragen nicht für das Training des Modells verwendet, um die Daten zu schützen.
Da Baum-Besitzer den KI-Assistenten ausprobieren möchten, aber nicht alle Nutzer sofort Zugriff haben sollen, kann die Berechtigung für die Nutzung auf bestimmte Nutzergruppen beschränkt werden.
Semantische Suche und KI-Chat sind standardmäßig deaktiviert und somit reine Opt-in-Funktionen.
Ausblick
Die Einführung des KI-Chat-Assistenten in Gramps Web eröffnet neue Möglichkeiten, mit genealogischen Daten zu interagieren. Anfangs sind die Fähigkeiten des Assistenten noch begrenzt, aber mit der grundlegenden Technik kann er mit Hilfe der Community stetig verbessert werden. Feedback und Beiträge sind entscheidend, um die Genauigkeit zu erhöhen, die Performance zu verbessern und komplexere Anfragen zu ermöglichen.
Im nächsten Beitrag geht es darum, wie man den neuen KI-Chat nutzt und was er kann – und was nicht.