 David Straub
David Straub
The new Gramps Web AI Chat Assistant – Technical Details
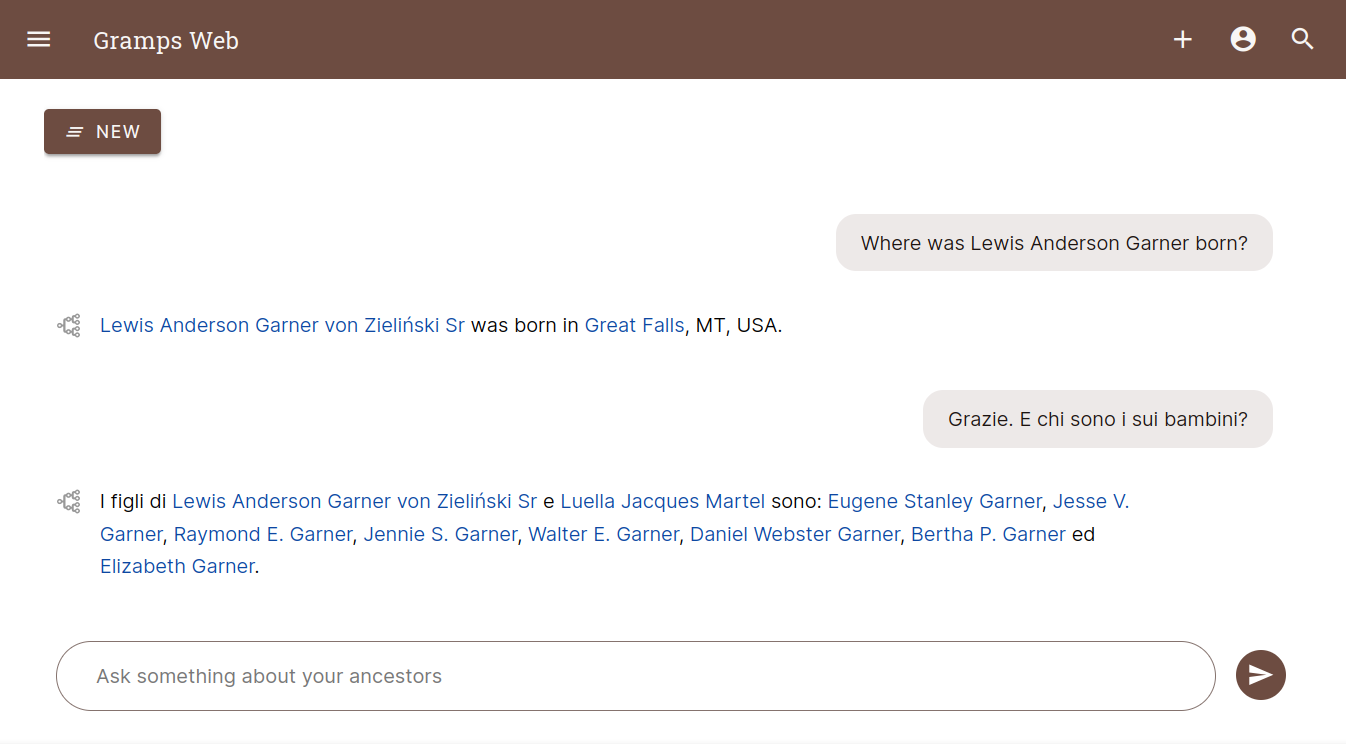
Starting with release 24.10, Gramps Web will be the first open-source genealogy system to feature an AI chat assistant! This post delves into the technical implementation of this exciting new feature, which allows users to interact with their genealogical data using natural language queries.
I’ll cover how Research Augmented Generation (RAG) powers the assistant, and the design choices that shaped its development. The next post will look at the tool from a user perspective, emphasizing current possibilities but also important limitations. The final post will be specific for Grampshub users. The new version is expected to roll out on Grampshub within the next month.
Research Augmented Generation
At the heart of the Gramps Web AI chat assistant is a technique called Research Augmented Generation (RAG), which combines semantic search with large language models (LLMs). RAG enables the system to formulate responses to user queries based on data in their genealogical database rather than relying on external knowledge, but does not require costly and time-consuming model training.
This is how RAG works:
Semantic Indexing: The first step involves transforming objects in the genealogical database into vector embeddings – numerical representations that encode their meaning. This is accomplished using a pre-trained embedding model from the open source Sentence Transformers library. The vectors serve as the foundation for future search queries, allowing the system to “understand” the content of the database in a semantically meaningful way.
Semantic Search: When a user asks a question via the chat interface, the query is similarly converted into a vector embedding. The system compares this query vector to the precomputed vectors of the database objects, using semantic similarity to find the most relevant results.
Answer Generation: The retrieved objects and the original user query are then passed to an LLM. The LLM synthesizes the information and formulates a coherent answer, based on both the genealogical records and the context of the question.
This combination of semantic search and LLMs allows the assistant to provide contextually rich responses, grounded in the user’s own genealogical data.
Vector Search for Semantic Understanding
One of the main building blocks of Gramps Web’s AI assistant is the use of vector search to enable semantic understanding of the genealogical data. Unlike traditional full-text search, which is based on keyword matching, vector search enables the system to understand the meaning behind user queries and genealogical records.
This approach allows the assistant to handle a wide range of user questions, even those that don’t directly match the text in the database. For example, a user could ask about “family members who immigrated” without needing to explicitly use the word “immigrate” in their records, because the vector embeddings capture semantic similarities across related terms and concepts.
Extending Gramps Web to support semantic search was facilitated by its integration with the Sifts library, which was extended specifically to handle the dual needs of full-text and vector-based searches. Sifts offers a unified, efficient interface for both types of search. With its dual database support, it allows to switch seamlessly between SQLite for lightweight setups and PostgreSQL for more robust, production-grade environments.
Embedding Model Selection and Trade-offs
An important consideration is the selection of the vector embedding model, which runs on the same server as Gramps Web. The Sentence Transformers library offers a variety of models, but the choice of model must balance accuracy, speed, and multilingual support.
Accuracy vs. Performance: Larger models offer better semantic understanding but require more computational power, especially if running on CPUs without GPU acceleration. Given that Gramps Web runs on a wide range of hardware – from desktop PCs to Raspberry Pi devices – a middle-ground model that provides decent multilingual support while being computationally efficient was pre-configured in the Docker images.
Multilingual Support: Since many genealogical records are multilingual, selecting a model with strong multilingual capabilities was critical. This ensures that users can query their data in different languages, and the assistant will still be able to generate meaningful responses.
Choice of LLM
Although Grampshub offers a hosted solution of Gramps Web with the aim to make using Gramps Web as simple as possible, it is always possible to self-host Gramps Web on a dedicated server. Due to this philosophy, the AI chat assistant was implemented with the option to host your own open-source LLM locally, with no need to send any data to the cloud. This is made possible by using Ollama.
However, running an LLM requires significant computational resources – even much more so than the vector embedding models – which is why it’s also easily possible to use an existing LLM API, e.g. the one of OpenAI, but also any other provider of your choice using a compatible API.
This approach allows users to choose a solution that best fits their infrastructure, whether they need the ease of use and scalability of a cloud-based LLM or prefer the privacy and control of a locally deployed model.
Privacy
Like all parts of Gramps Web, the data users can see depends on their permissions level. Users who do not have the permission to view records marked as private will not see any such data in responses, nor will the LLM see such data when generating a response.
When using an API, an important consideration is to make sure to use a service where user queries are not used for model training, to ensure your data is protected.
Since owners of a Gramps Web tree might be interested in trying out the AI assistant but might not want all of their users to have immediate access to this feature, permission to use it can be restricted to specific user groups.
Semantic search and AI chat are disabled by default, and are thus pure opt-in features.
Outlook
The introduction of the AI chat assistant in Gramps Web opens up new possibilities for interacting with genealogical data. Initially, the assistant’s capabilities will be quite limited, but with the foundational technology in place, it can be steadily improved with the help of the community. Feedback and contributions will play a key role in refining its accuracy, enhancing performance, and expanding its ability to handle more complex queries.
Stay tuned for the next post, where we will focus on how to use the new AI chat, and what it can – and can’t – do for you.